I think many will agree with me when I say that good data analysis is often fueled by great coffee. Living where I do, the Pacific Northwest region of the US, we have a bit of a coffee (and beer) culture and my palette has become spoiled by the many great local coffee shops serving your choice of locally roasted single varietal beans (Ethiopian Duromina or Indoesian Gajah Acehc, anyone?). Unfortunately, due to the way most of my days unfold, I usually don’t have the time to make the trip to a local shop to buy an espresso (which happens to be my drink–3-4 shots of espresso, a tiny dollop of milk and a half a packet of sweetener).
The good news is, a few years ago, I discovered the moka pot (or stovetop espresso machine), and it is now a part of my everyday routine. Which glosses over the point that it makes some really… really good coffee. So, for those of you who have yet to give it a shot (did you see what I did there…) here are my tips and tricks for making a great pot of coffee with one of these devices.

Bialetti Moka Express
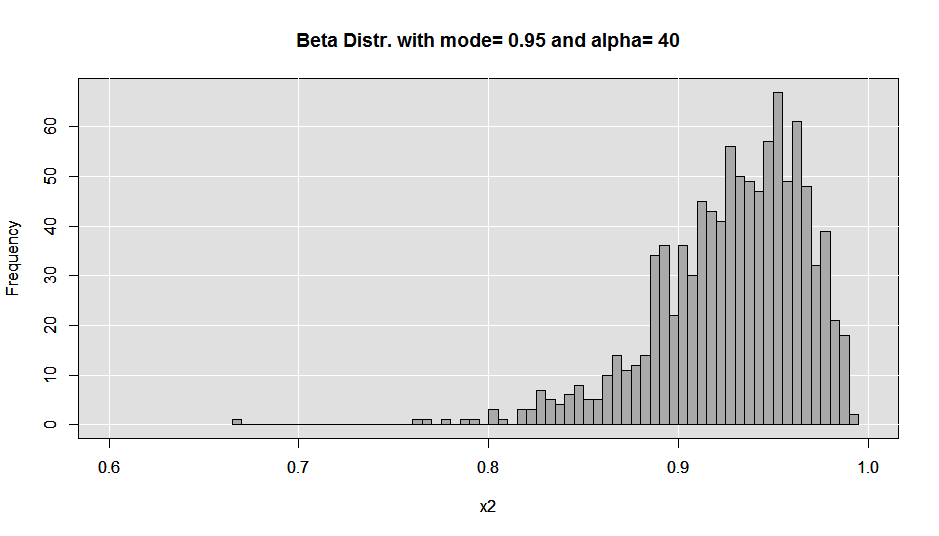
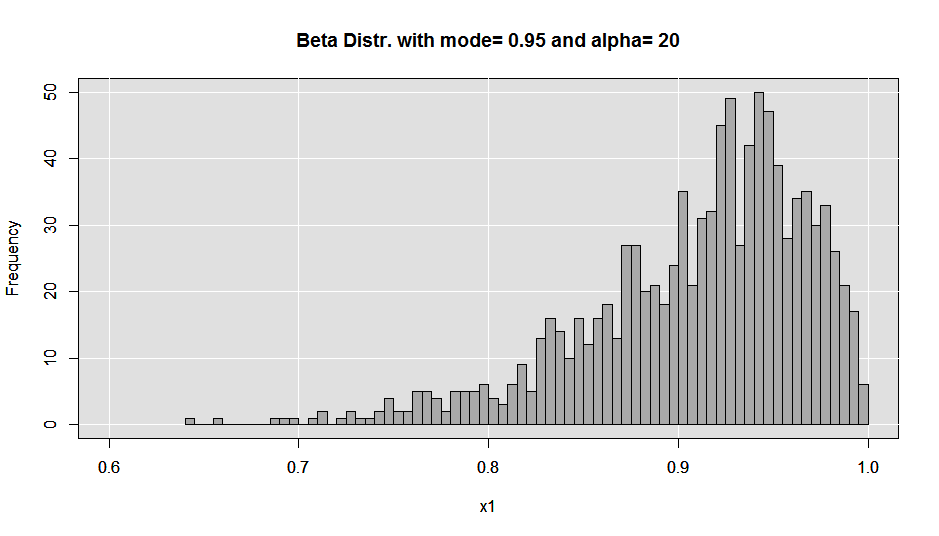
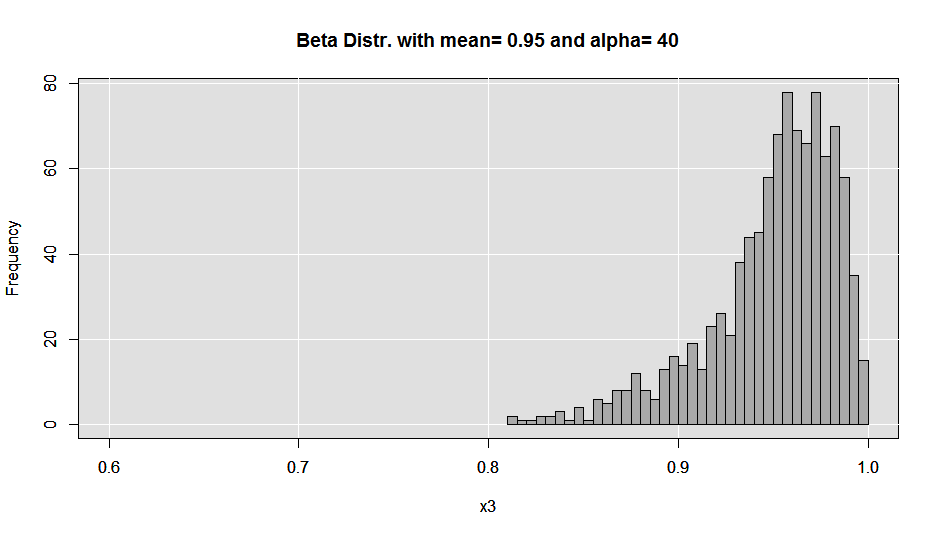
In terms of tools and ingredients all you need are a Moka pot (I purchased a Bialetti from Amazon, but I’m sure you can find one locally if you prefer), some finely ground dark roast coffee beans and some clean water. I use a 9-cup maker and I find that it provides the 3 “triple shot”-sized servings I require to make it through a day.
When making a coffee with one of these the first thing you need to do is fill the water reservoir. There should be a raised mark inside of the reservoir cylinder to use as a guide. DO NOT fill over this mark, as you will disable the proper functioning of the pressure release valve. I tend to under-fill by just a bit.

This is about where I fill to
Next fill the coffee chamber with ground beans. Experiment with different roasts/blends until you find what you like. While I do sometimes splurge on locally micro-roasted single varietals, I do also find that Starbucks Verona or Espresso roast do well as daily drinkers. Here is where my method of brewing differs from what I’ve read from various sources. Most instructions will tell you not to pack or tamp the grinds down in the chamber. While I do not vigorously pack the grinds in, I do take the back of a tablespoon and gently apply some pressure to the beans in the chamber to smooth out the top layer. If you are incapable of applying only a small amount of force, I’d just skip this step.

DO NOT press with much force… a gentle tamp will do.
Lastly, I set the gas burner on our stove to medium-high, and wait for the magic to happen (the cook time will vary with your BTUs/the size and type of Moka pot, etc.,). This is where there will have to be some trial and error on your part. Also, the cooking procedure is where I’ve read different advice as well. Some will say to set your burner on high, for example. What I find is that, If I set the burner on medium-high, I have a greater amount of control over the very end of the cook, which is an important part of the process for me. At medium-high, I can come back to the pot when the cook is almost finished and turn the burner off for the very last stages of the brew. Turning off the heat stalls pressurization within the water chamber and allows the water vapor to push its way through the grinds with slightly less force at the end of the cook forming a pseudo-crema at the end of the cook. This is in contrast to the forceful popping and gurgling you will experience if you keep the burner on high until the end.

My pseudo-crema…
Next, pour and enjoy! Now, go out and make some great data analysis!