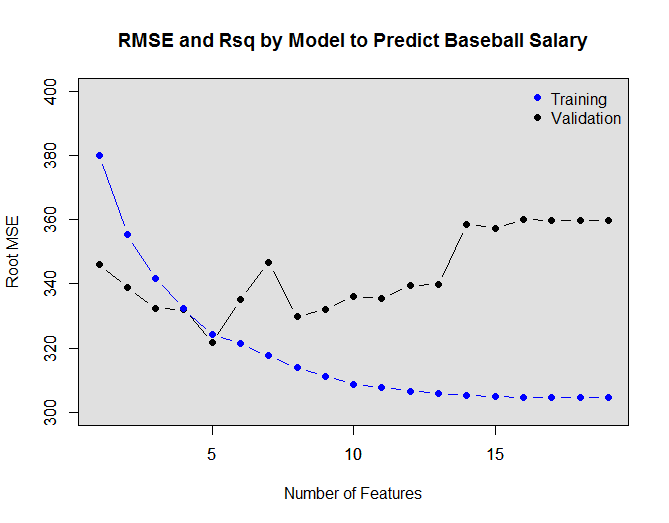
By this it appears that the best model to predict baseball salaries includes 5 features.
I’ve been having a lot of fun taking part in a Stanford MOOC called “Introduction to Statistical Learning” offered by Dr. Trevor Hastie and Dr. Robert Tibshirani. The class parallels the book of the same name. The course has been AMAZING so far. And so far we’ve even been blessed with a cameo appearance from another author Daniela Witten! I wonder ,if before it’s over , we’ll hear from Gareth James (another one of the ISLR authors).
Anyhow, the class recently spent some time on model selection. We covered best subset, forward selection, backward selection, ridge regression and the lasso. One of the big takeaways for me has been the value of doing cross-validation (or K-fold cross-validation) to select models (vs. relying on Cp, AIC or BIC). Well, given you can even calculate them (for ridge and lasso, since you don’t really know the number of coefficients, d, you couldn’t even estimate these if you wanted to). That said, Dr. Hastie let the class in on a very handy custom function for cross-validation. I spent some time walking through it and present it (step-by-step) below.
In the example the dependent variable (Salary) is quantitative, and the features (IVs) are of various types. The object is to find the linear model that best captures the relationship b/w the features and Salary. They key here is to avoid over-fitting the model. We seek to optimize the variance-bias tradeoff, and so instead of relying on R-squared or even other corrected/improved indicators like Cp, AIC and BIC, in this case we employ cross-validation to determine the size of the model… I’m becoming a fan of this approach.
First, here’s the chunk all at once:
require(leaps)
set.seed(1)
train=sample(seq(nrow(Hitters)),round(2/3*nrow(Hitters), 0) ,replace=FALSE) # create training sample of size 2/3 of total sample
train
regfit.fwd=regsubsets(Salary~.,data=Hitters[train,],nvmax=19,method="forward")# fit model on training sample
val.errors=rep(NA,19) # there are 19 subset models due to nvmax = 19 above
x.test=model.matrix(Salary~.,data=Hitters[-train,])# notice the -index!... we are indexing by minus train, so this is our test sammple
for(i in 1:19){
coefi=coef(regfit.fwd,id=i)# returns coeficients only for model model i from 1-19
pred=x.test[,names(coefi)]%*%coefi # names(coefi) pulls only columns from model = i, then matrix multiply by the coeficients from i (coefi)
val.errors[i]=mean((Hitters$Salary[-train]-pred)^2)
}
plot(sqrt(val.errors),ylab="Root MSE",ylim=c(300,400),pch=19,type="b")
points(sqrt(regfit.fwd$rss[-1]/180),col="blue",pch=19,type="b")
legend("topright",legend=c("Training","Validation"),col=c("blue","black"),pch=19)
Line 1 (Building a place to store stuff)
val.errors=rep(NA,19)
Line 1 is all about efficiency, what you are doing here is, essentially, building an empty vector of 19 NAs (which will serve as a kind of shelf to store something you will make later on). Those somethings are the 19 test RMSE, that you will produce with your function.
Line 2 (gathering one key ingredient)
x.test=model.matrix(Salary~.,data=Hitters[-train,])# notice the -index!
This is where you create your test set of data. I think the really cool thing going on in this line is how the model.matrix function works. By running the piece of code below, you’ll see that it produces something similar to Hitters[-train,], but by using some additional specification (in the formula Salary~.) you tell it to remove the salary variable and include a vector of 1s which it reserves for an Intercept term (important during the matrix multiplication step).
Try this and you can see how model.matrix does it’s work:
model.matrix(Salary~.,data=Hitters[-train,])
Line 3 (Getting loopy…)
for(i in 1:19){
This line just specifies how you want your loop to run. Remember you are looping from 1-19 because you created 19 distinct models using the nvmax=19 above in regsubsets().
Line 4 (Why looping constructs are cool)
coefi=coef(regfit.fwd,id=i)
Here you are putting the index (i) that the loop is looping through to good use. As the loop does it’s thing it will use this piece of code to create 19 different vectors, one for each model returned by regsubsets above. Don’t take my word for it, try this:
coefi=coef(regfit.fwd,id=6)
Line 5 (The magic of matrix multiplication)
pred=x.test[,names(coefi)]%*%coefi
Lots of good stuff going on here, one of which being the use of the names() function to ensure that for each model you are only doing multiplication on the correct number of columns, but here was one of my big A-HAs. What you have to remember (or realize) here is that the vector coefi (which you create above) is multiplied by the matrix x.test (which is of dimensions nxp). This will return a vector of nX1. Where each scalar is the prediction value for the model of interest. At the end of the day pred will contain all of your individual yhats. Don’t believe me, try this:
coefi=coef(regfit.fwd,id=6) pred=x.test[,names(coefi)]%*%coefi
Line 6 (Time to calculate your individual test errors and put them somewhere)
val.errors[i]=mean((Hitters$Salary[-train]-pred)^2)
Here is the line where you are putting all of the individual ingredients, making your final product, and putting it away for safe keeping (remember that vector of NA you built earlier). In this piece:
(mean((Hitters$Salary[-train]-pred)^2)
..you are calculating your MSE using your yhats (pred) and your actual ys (Hitters$Salary[-train]). You use the index from your loop to put your MSE away in its respective spot in the vector of NAs with val.errors[i].
The loop will iterate over all your i (1-19), and that’s how it all comes together! Very cool indeed. While you can certainly don’t need to take a look under the hood, I find that to really “get” the pleasure, it helps to stop and think about the complexity. (I think I’m really butchering a Feynman quote there).
The rest of the code just does some plotting so you can visualize at which model size you reach the minimum of RMSE. The overlay of Rsq is a nice touch as well.
Just in case you were curious, the 5 coefficient model happens to be this one (it is important to note that Salary is in $K):
Salary = 145.54 + 6.27*Walks + 1.19*CRuns – 0.803*CWalks – 159.82*DivisionW + 0.372*PutOuts
I thought it was strange that it doesn’t appear to matter in what league you played, but it did matter what division you played in (most likely an AL East “effect”). Anyhow, to learn more about the individual features of the model you can see further documentation on the Hitters dataset here.